本文共 1355 字,大约阅读时间需要 4 分钟。
来源于李宏毅老师机器学习课程,笔记是其中meta learning部分,few-shot learning学习也可以观看此部分课程。
课程主页:
video:bilibili:
Gradient Descent as LSTM
上一次讲到通过学习初始化参数的meta learning方法,那么是否有更多的方法呢?
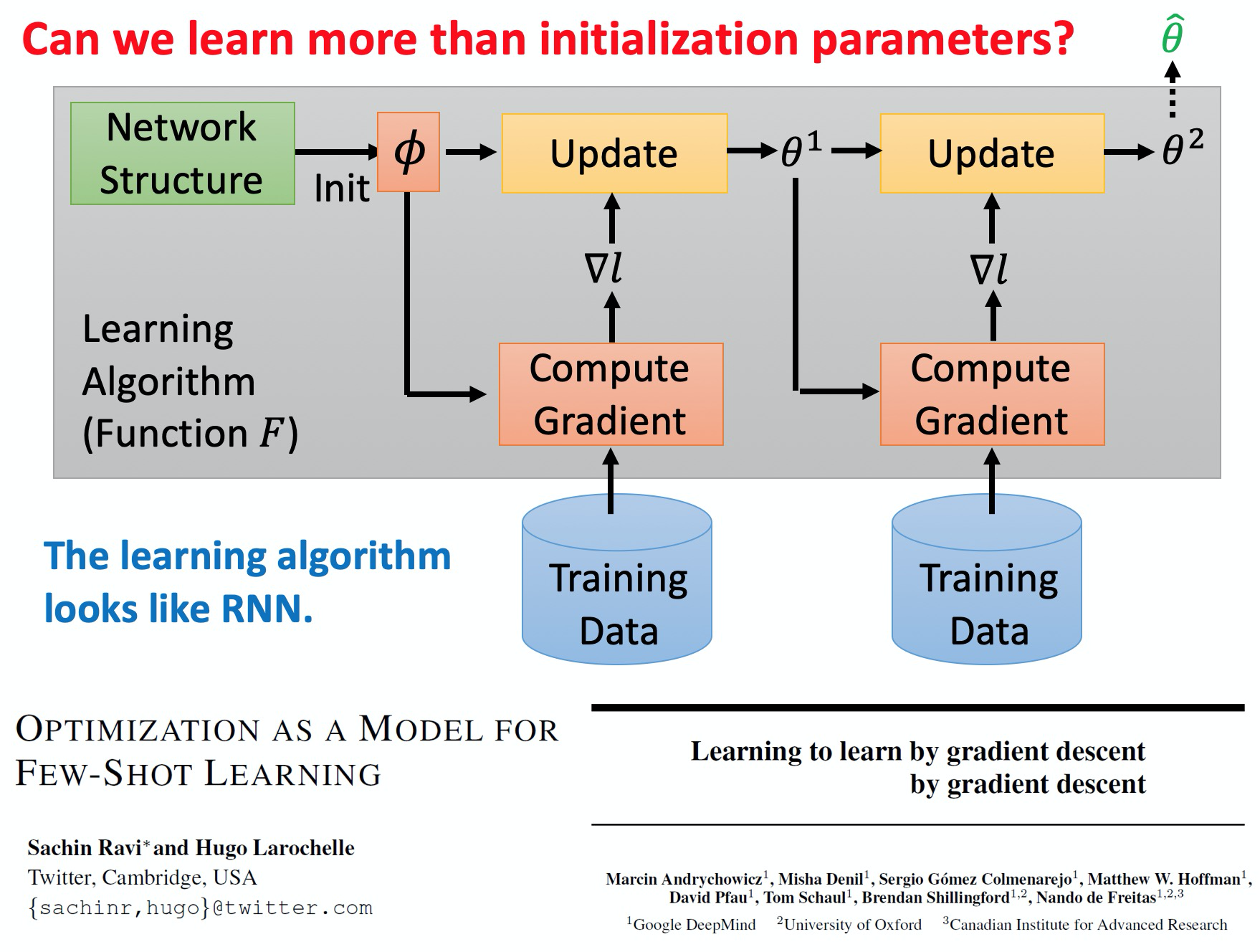
每一次的update的,会很像RNN的time step,每一步训练都会更新参数,那么RNN是否可以用于meta learning呢?
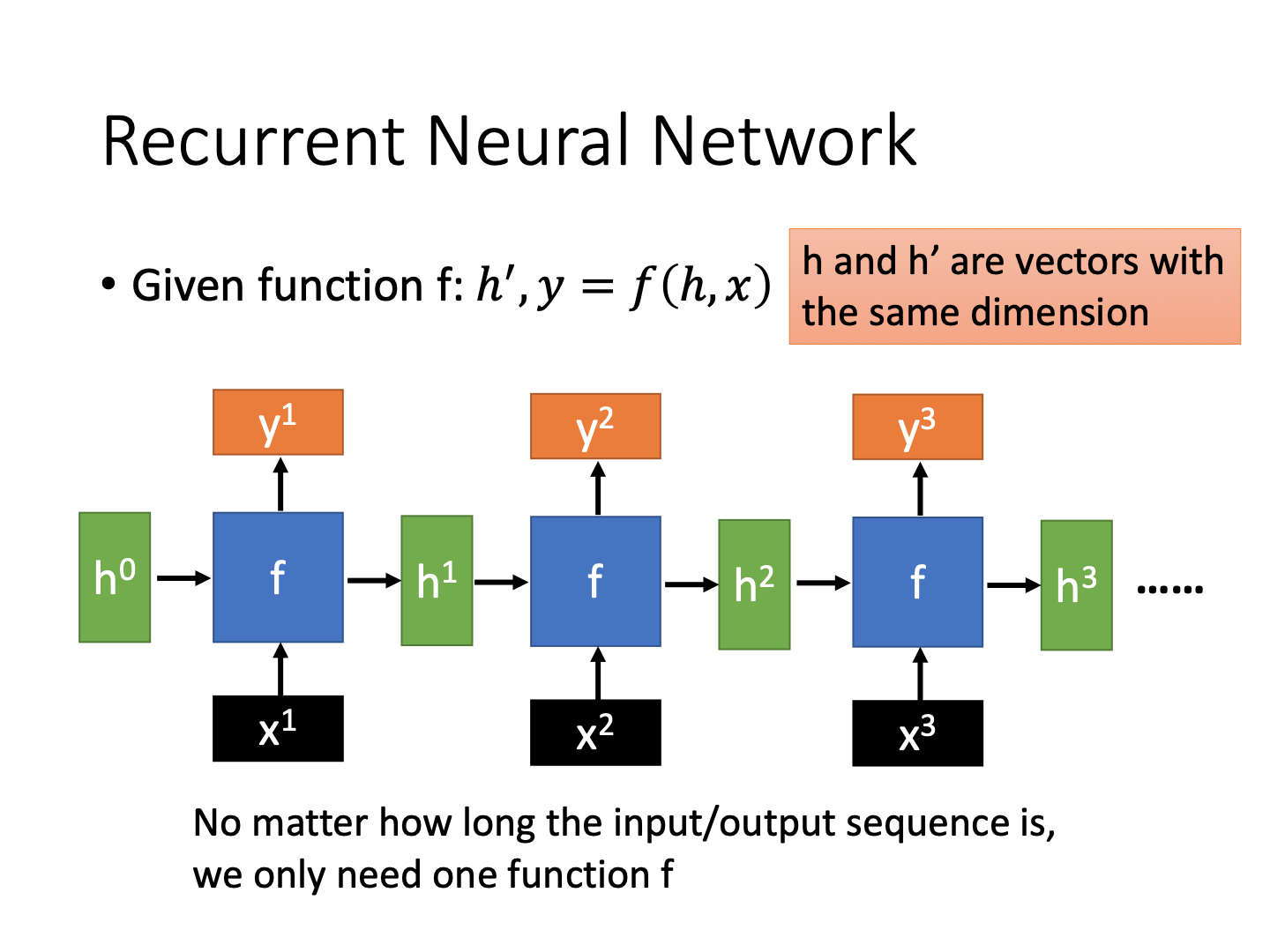
那么RNN和lstm的原理是什么样的呢,这里先做了一些介绍,其实看图就让人回忆起来了。
详细原理可以参考:
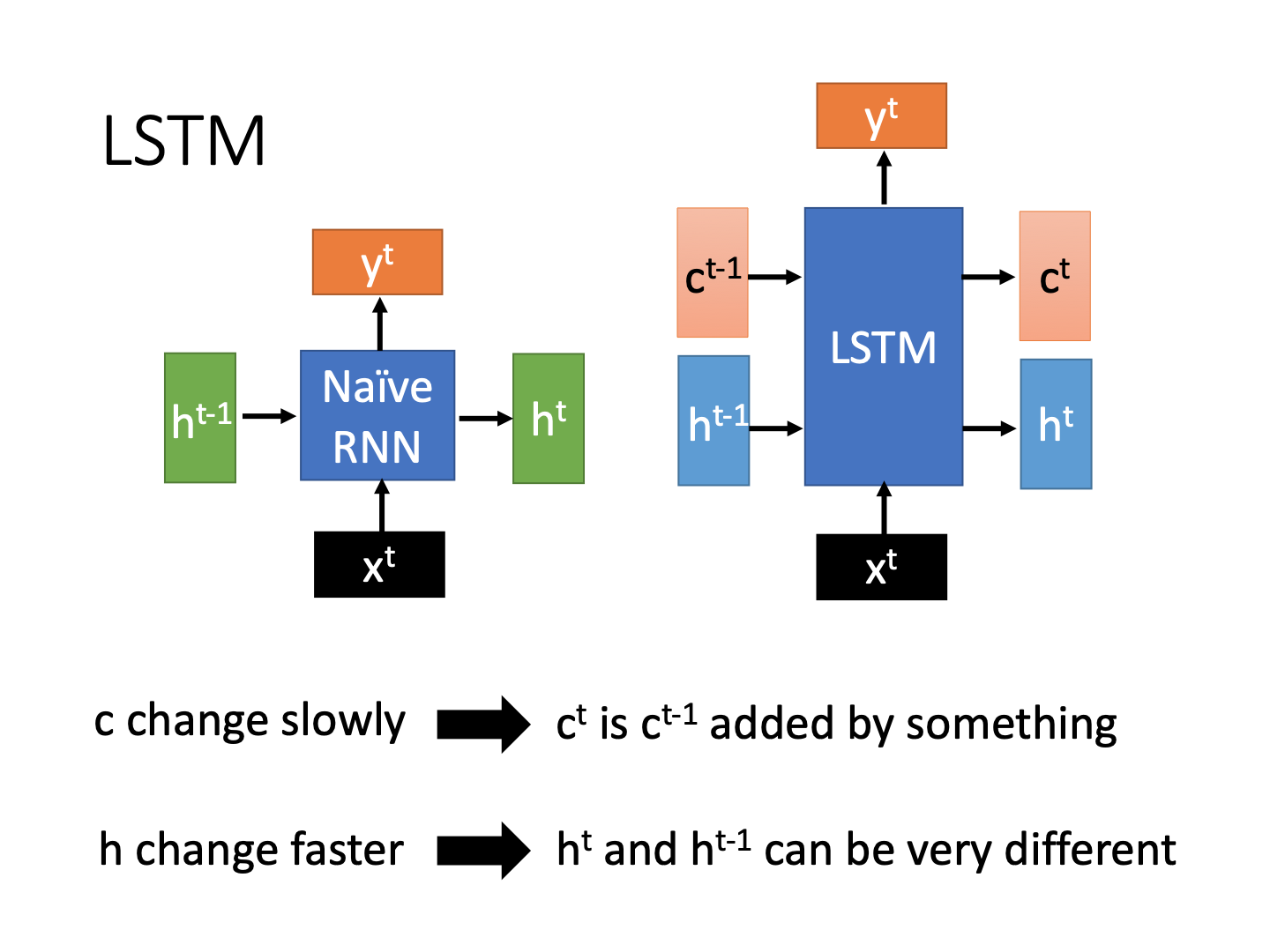
LSTM由于加入了cell单元,相对于RNN会有更长期的记忆。具体原理下面会进行回顾
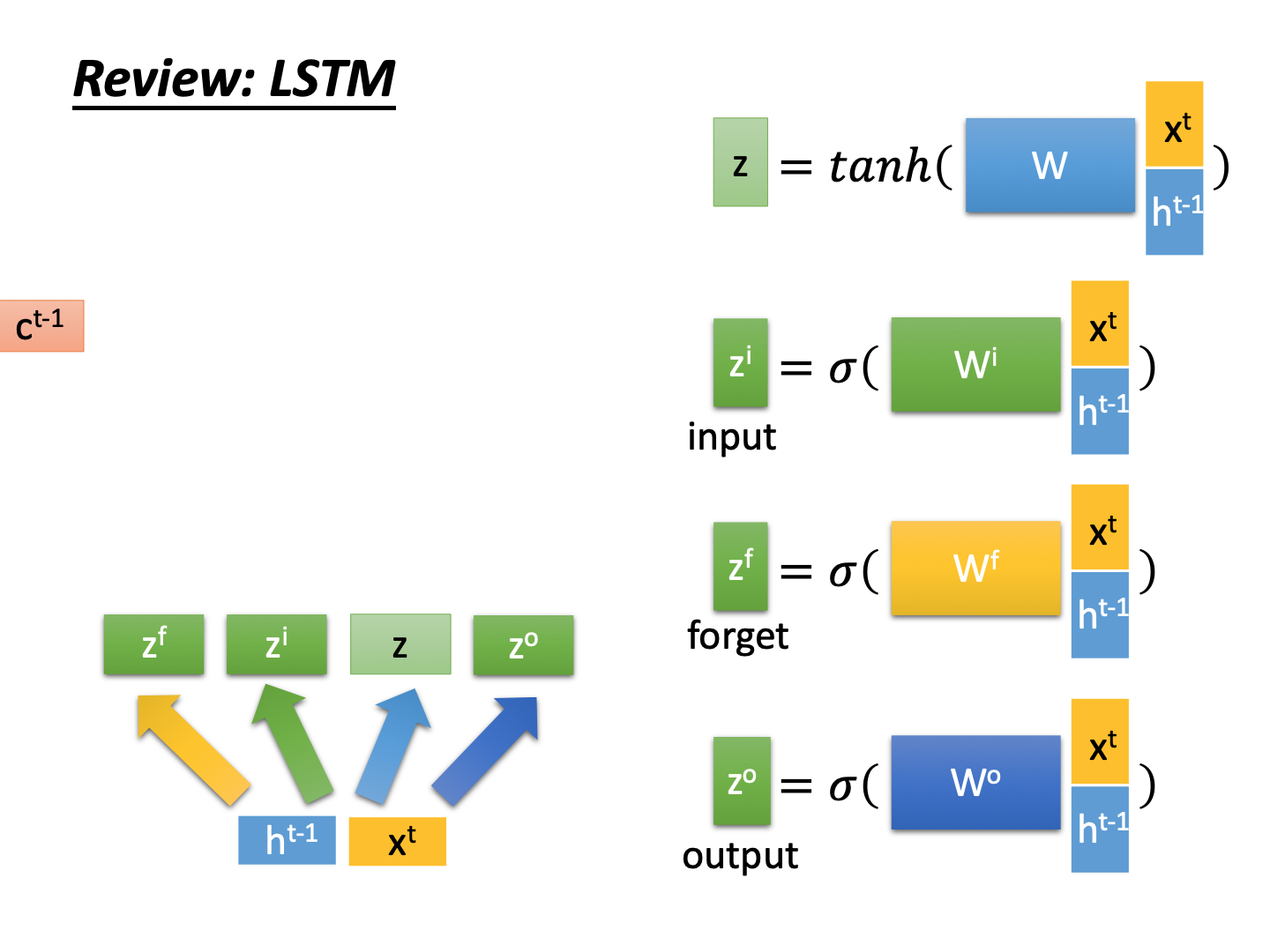
首先是输入向量z, 以及三个门(输入门、遗忘门、输出门)计算公式。
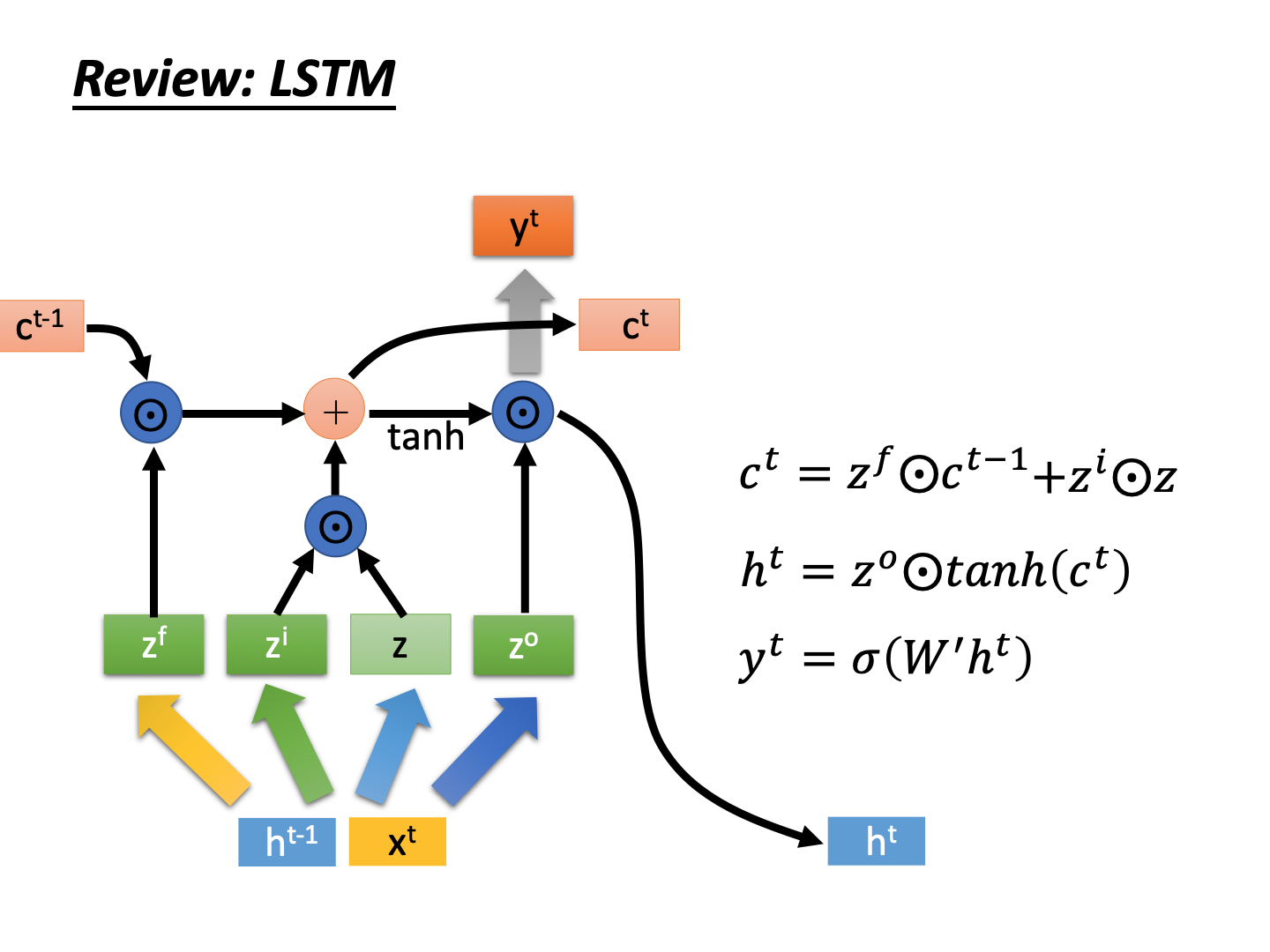
然后图中是lstm的输出: c t , h t , y t c^t,h^t, y^t ct,ht,yt的计算公式。
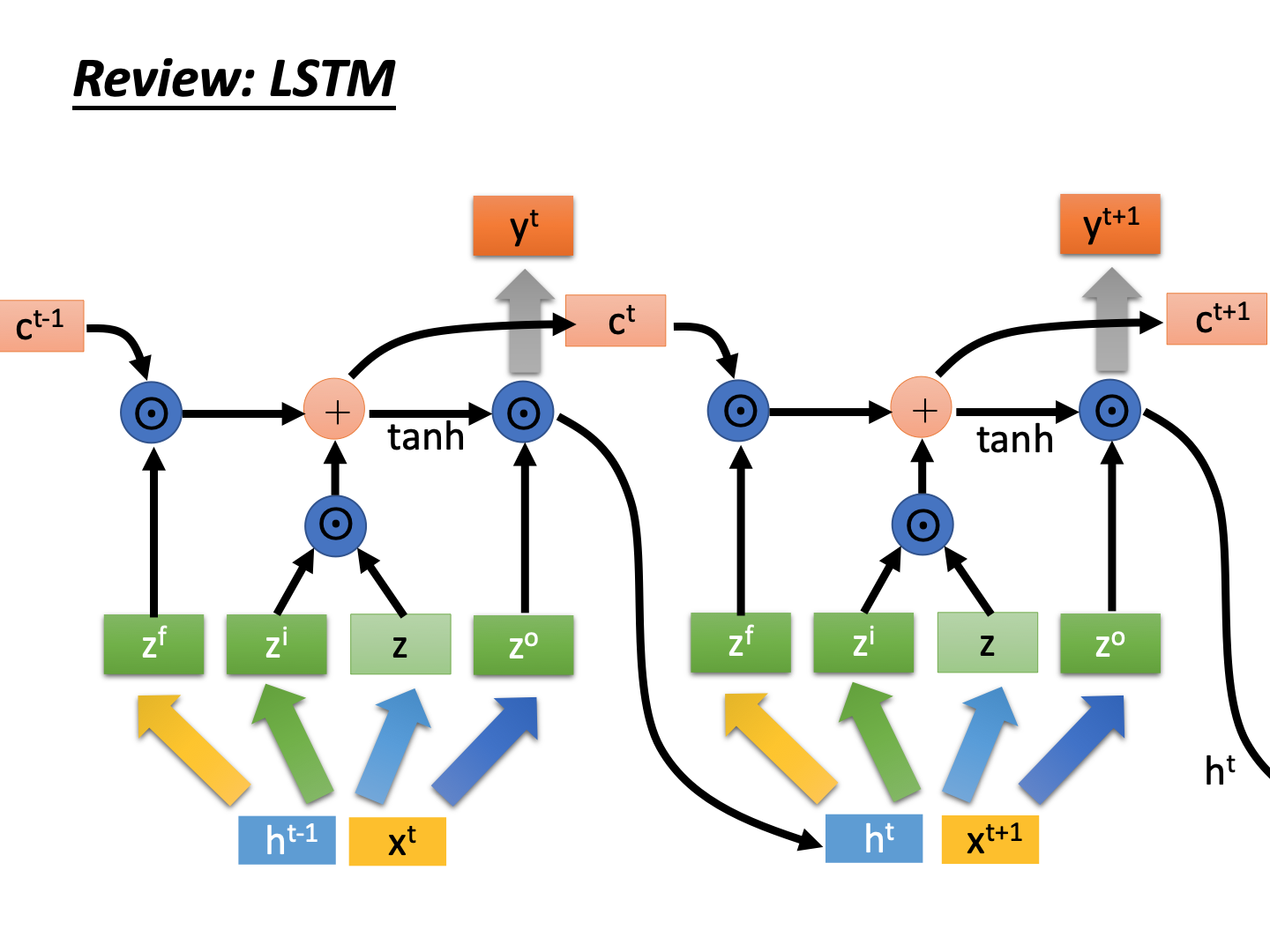
然后每一次都反复每个time step的步骤,就是LSTM的计算过程。
那么和meta learning会有什么关系呢?
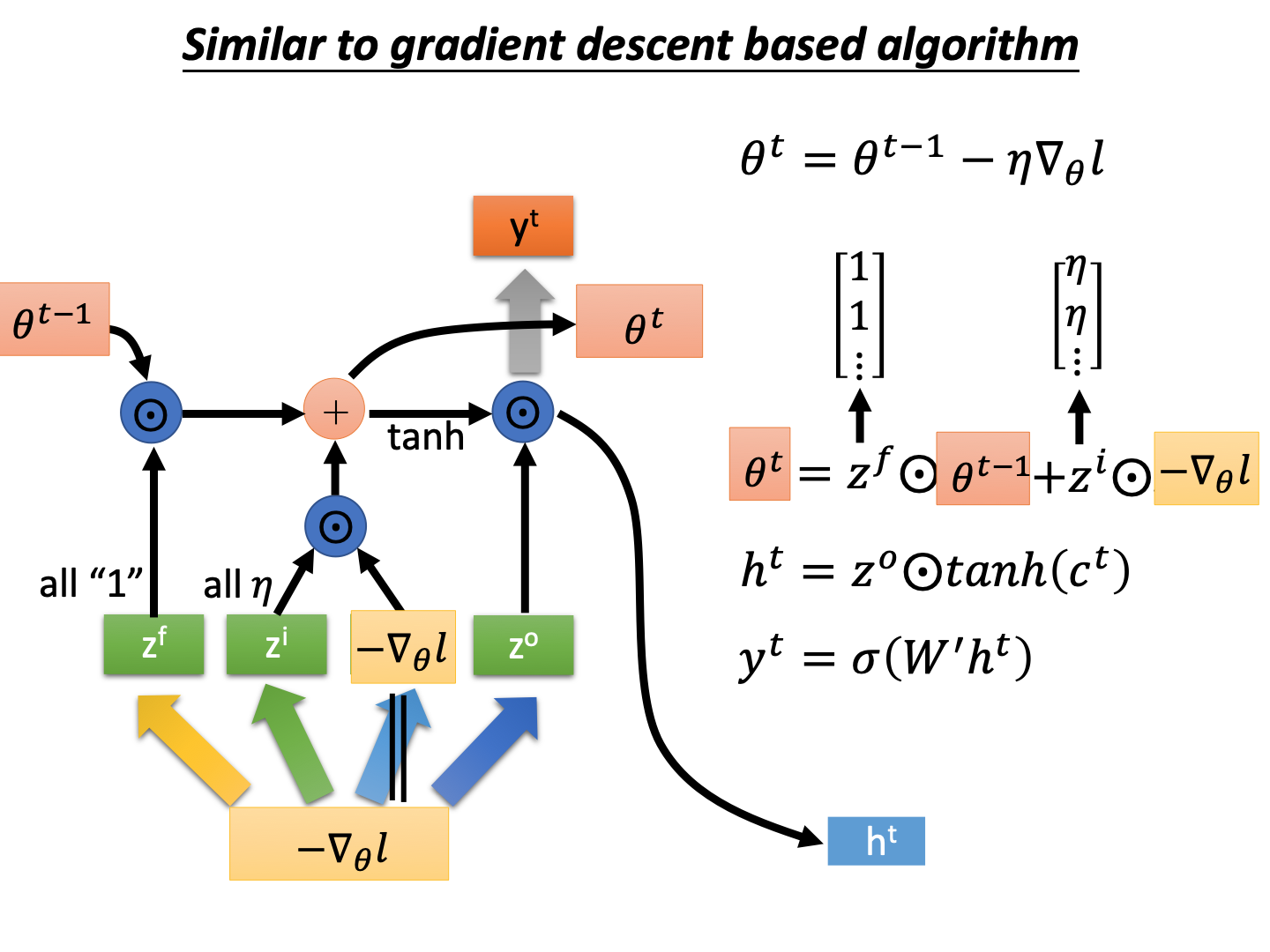
梯度下降过程中,每个time step会通过梯度来更新参数 θ \theta θ,和LSTM中c很相似,那么LSTM中c是否也可以用 θ \theta θ来代替呢?
如图,将遗忘门 z f z^f zf置为全1的矩阵,将输入门 z i z^i zi所有元素置为meta learn的学习率。
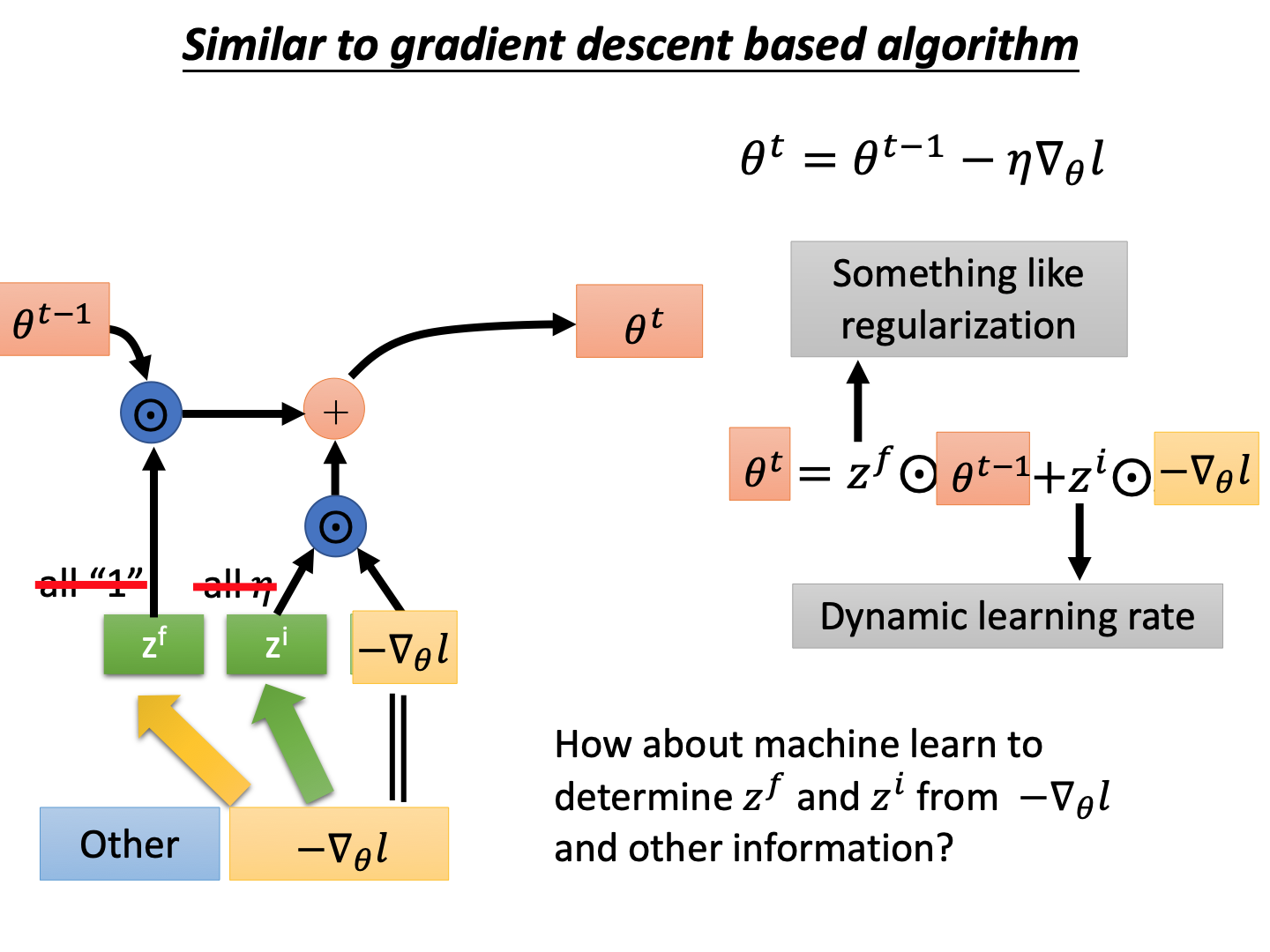
实际过程中,当前time step的输入还可以引入更多东西(图中other),可以是当前参数 θ t − 1 \theta^{t-1} θt−1的loss等。
同时, z f , z i z^f,z^i zf,zi是固定的,能否通过学习得到呢?即:
- z i z^i zi:自动学习给出适合当前的学习率。
- z f z^f zf自动学习出做多少weight decay。 z f z^f zf是将之前的参数缩小,和weight decay一样的作用。
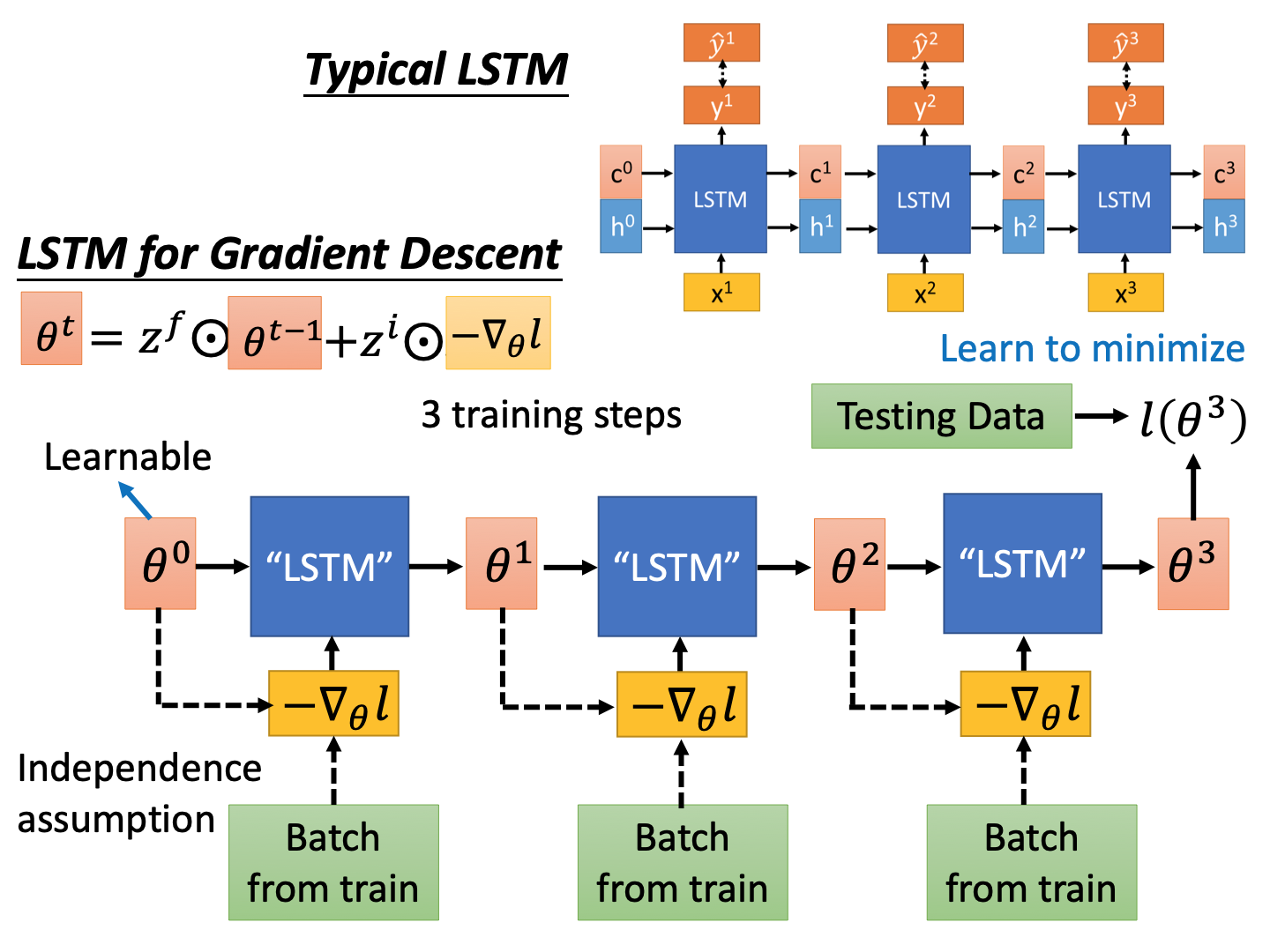
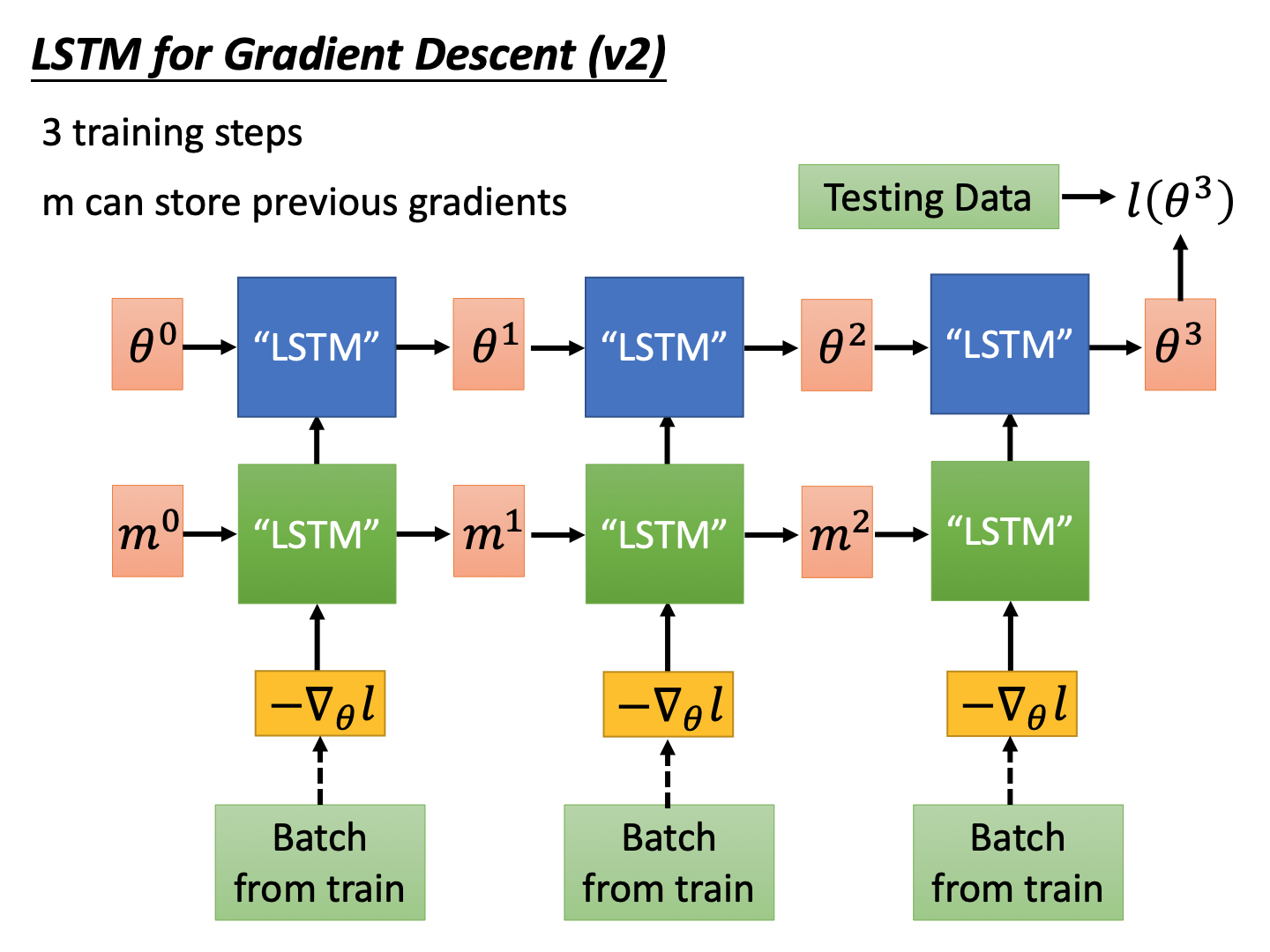
图上面是一般的lstm结构,下面是gradient descent中的lstm,对于初始参数 θ 0 \theta^0 θ0,训练集中mini batch输入可以获得其梯度,然后更新参数的过程为:
θ t = z f ⊙ θ t − 1 + z i ⊙ − ∇ θ l \theta^{t}=z^{f} \odot \theta^{t-1}+z^{i} \odot^{-\nabla_{\theta} l} θt=zf⊙θt−1+zi⊙−∇θl 同时每次的batch不一样,并且参数不一样,对应的梯度 − ∇ θ l -\nabla_{\theta} l −∇θl也是不一样的(这里符号上没有做区别)。图中就是一个训练数据集的三次参数update的过程,然后这个是“lstm”网络的前馈过程,然后使用训练数据,计算获得损失 l ( θ 3 ) l(\theta^3) l(θ3),然后使用梯度更新“lstm”参数来使得损失最小。(这里有点套娃)
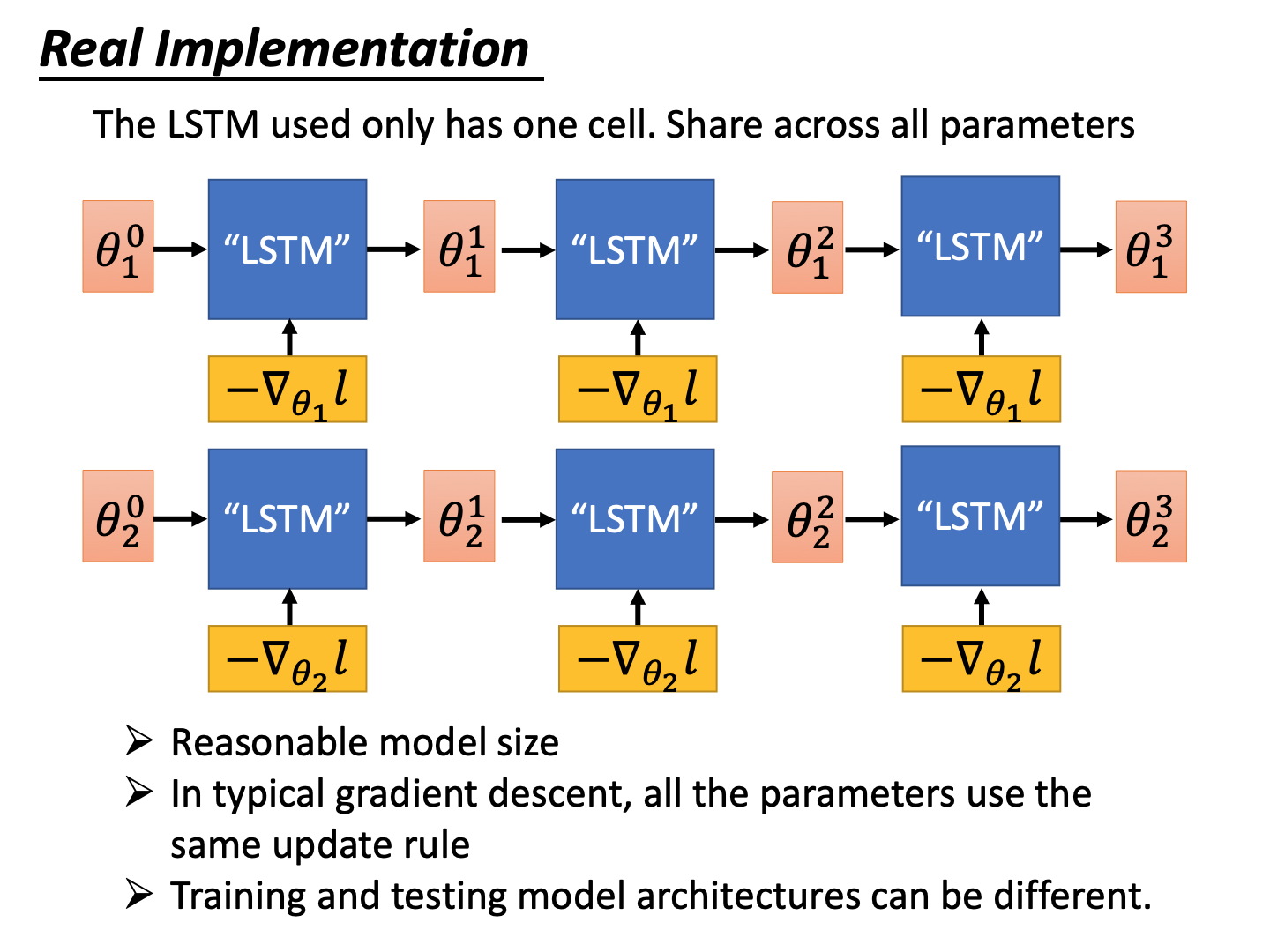
由于参数 θ \theta θ的数量巨大,不能直接输入“lstm”,所有会将所有维度的参数都复用一个“lstm”的cell。
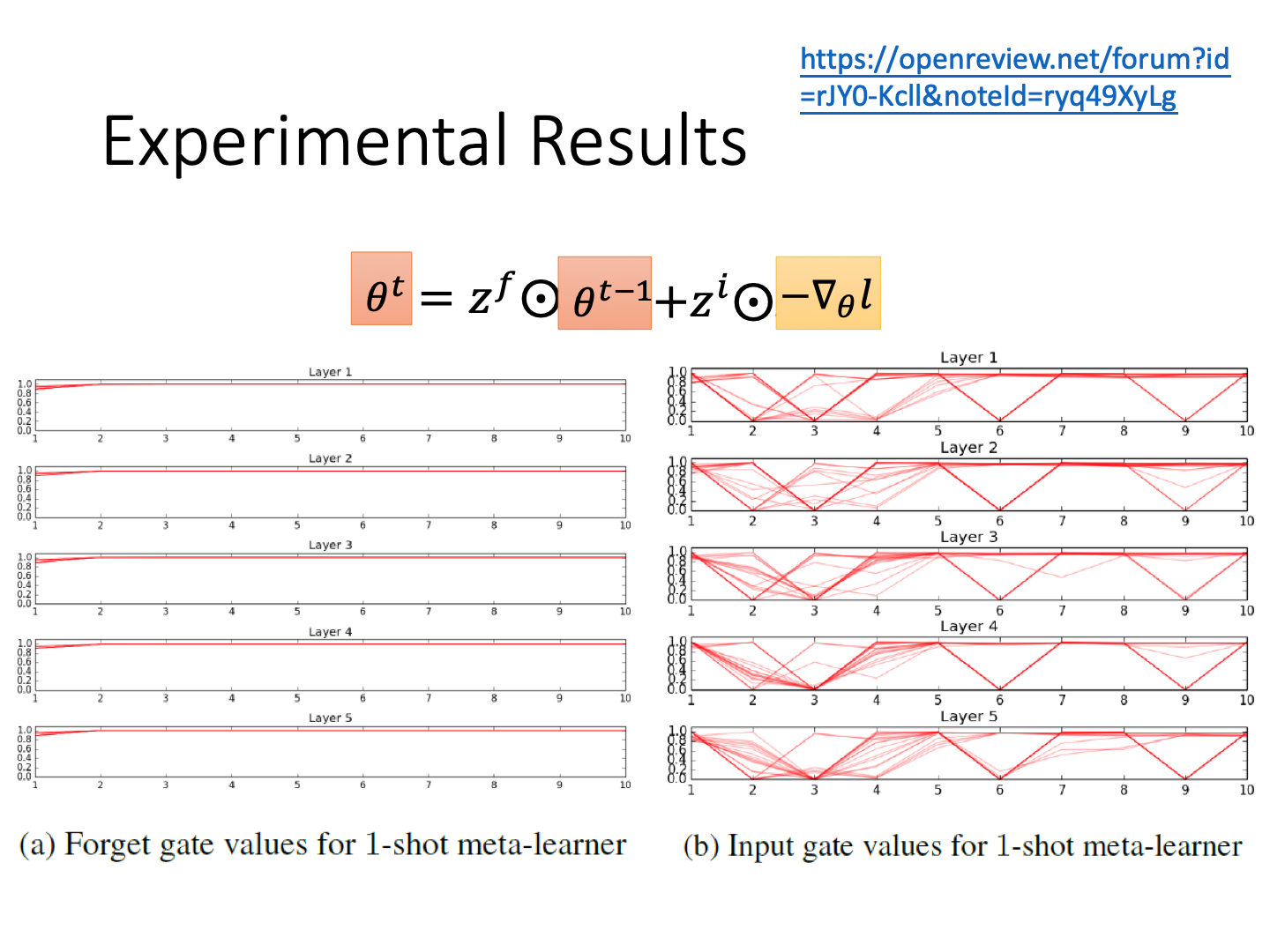
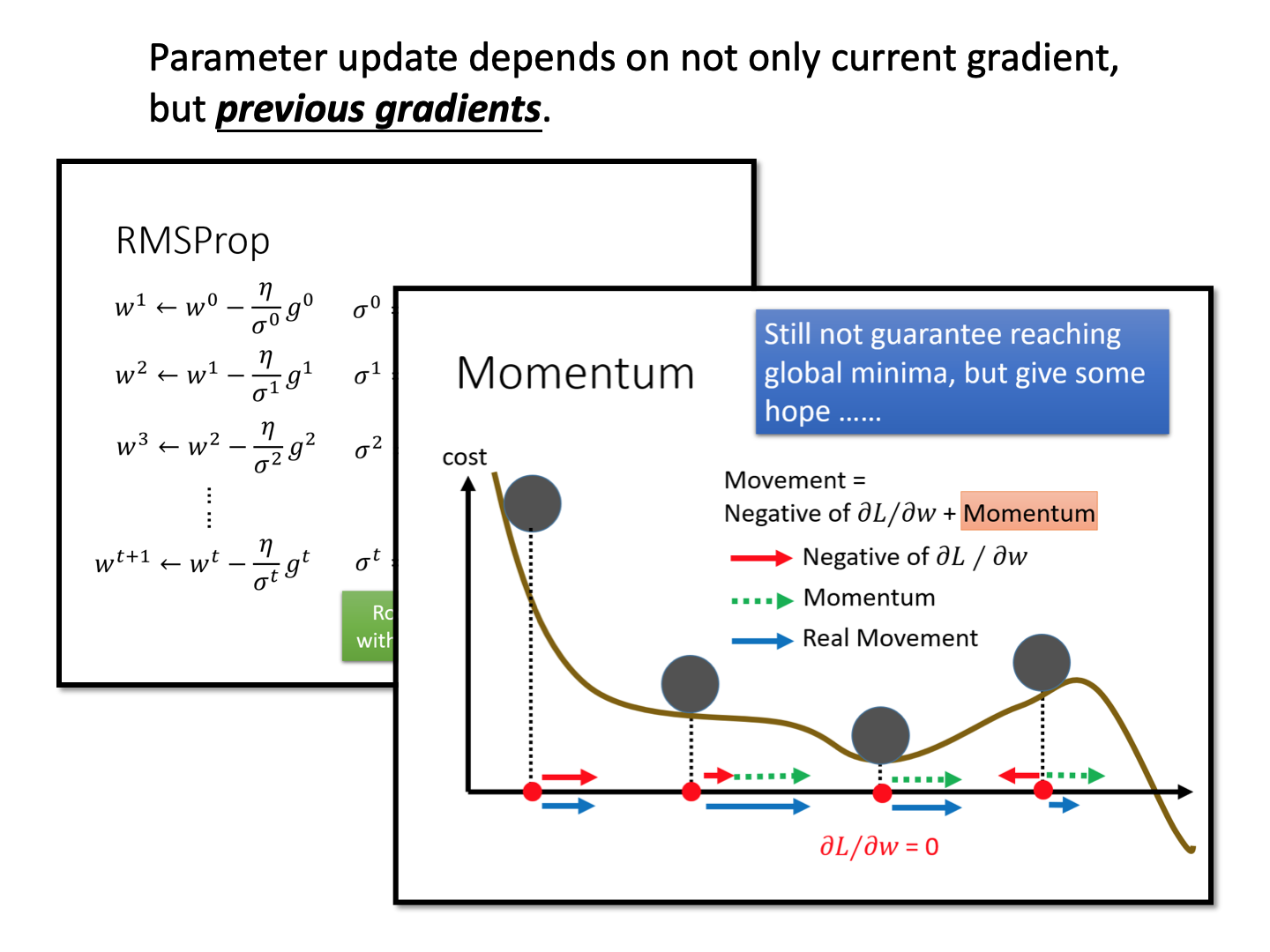
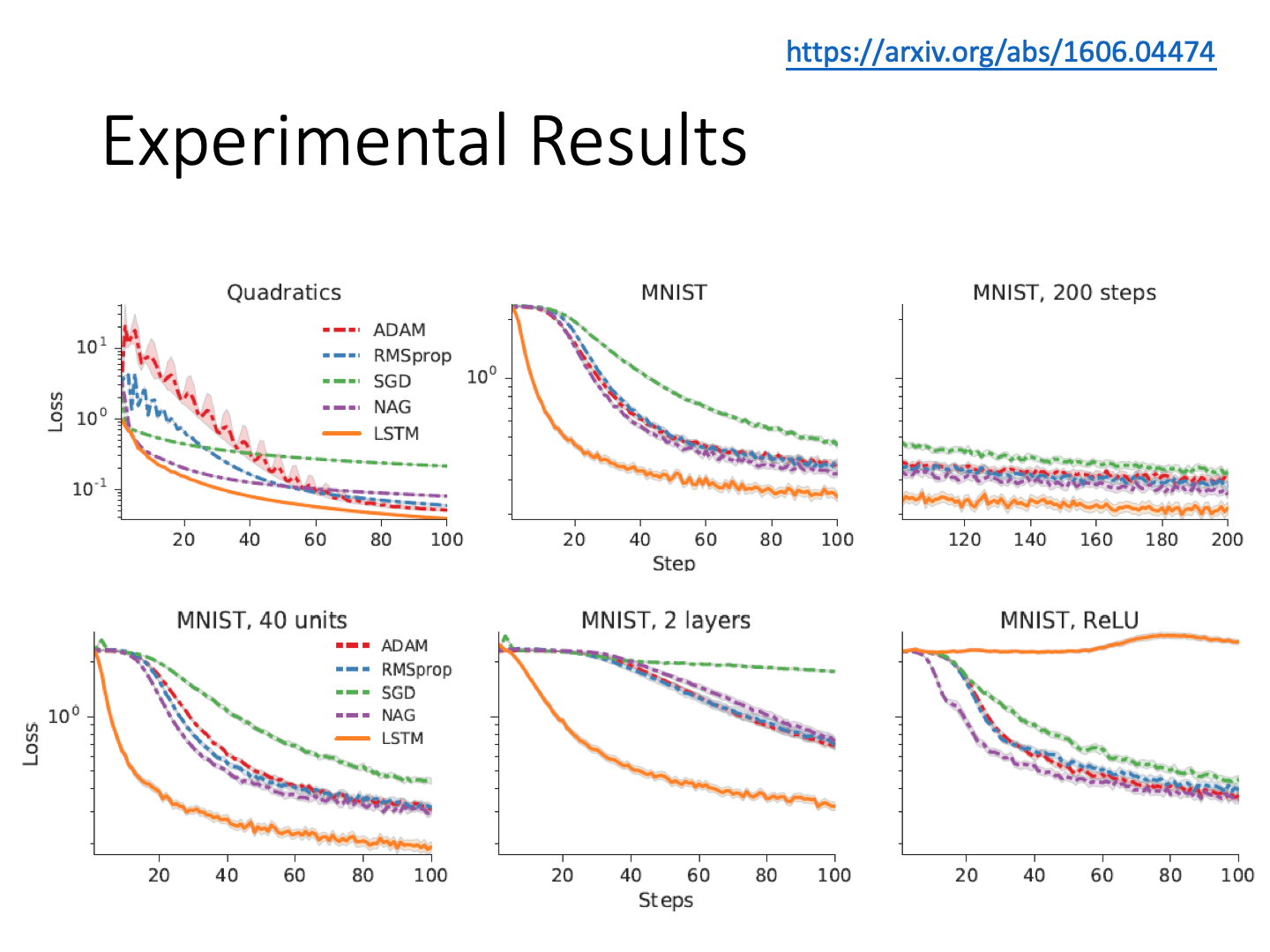
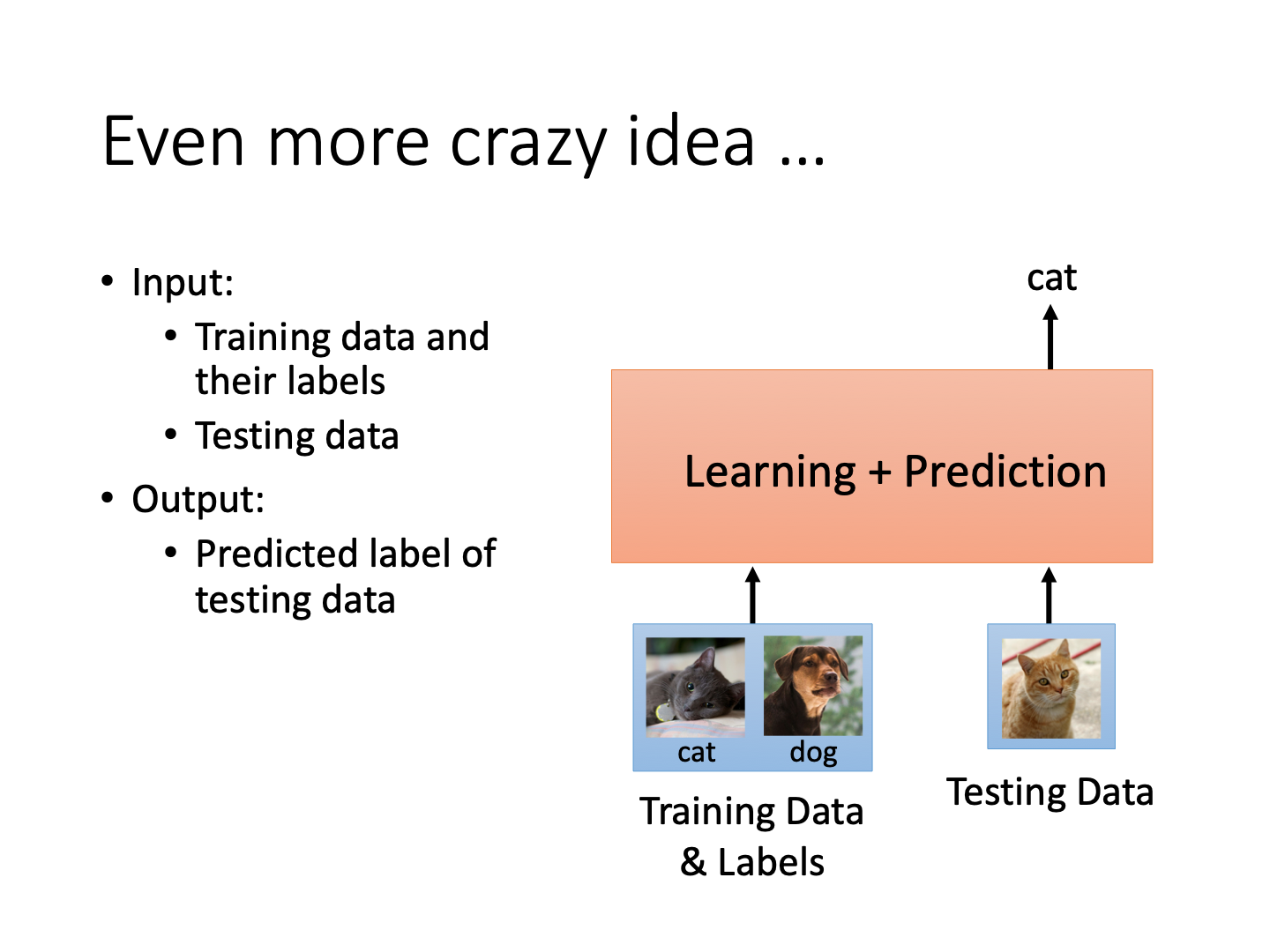
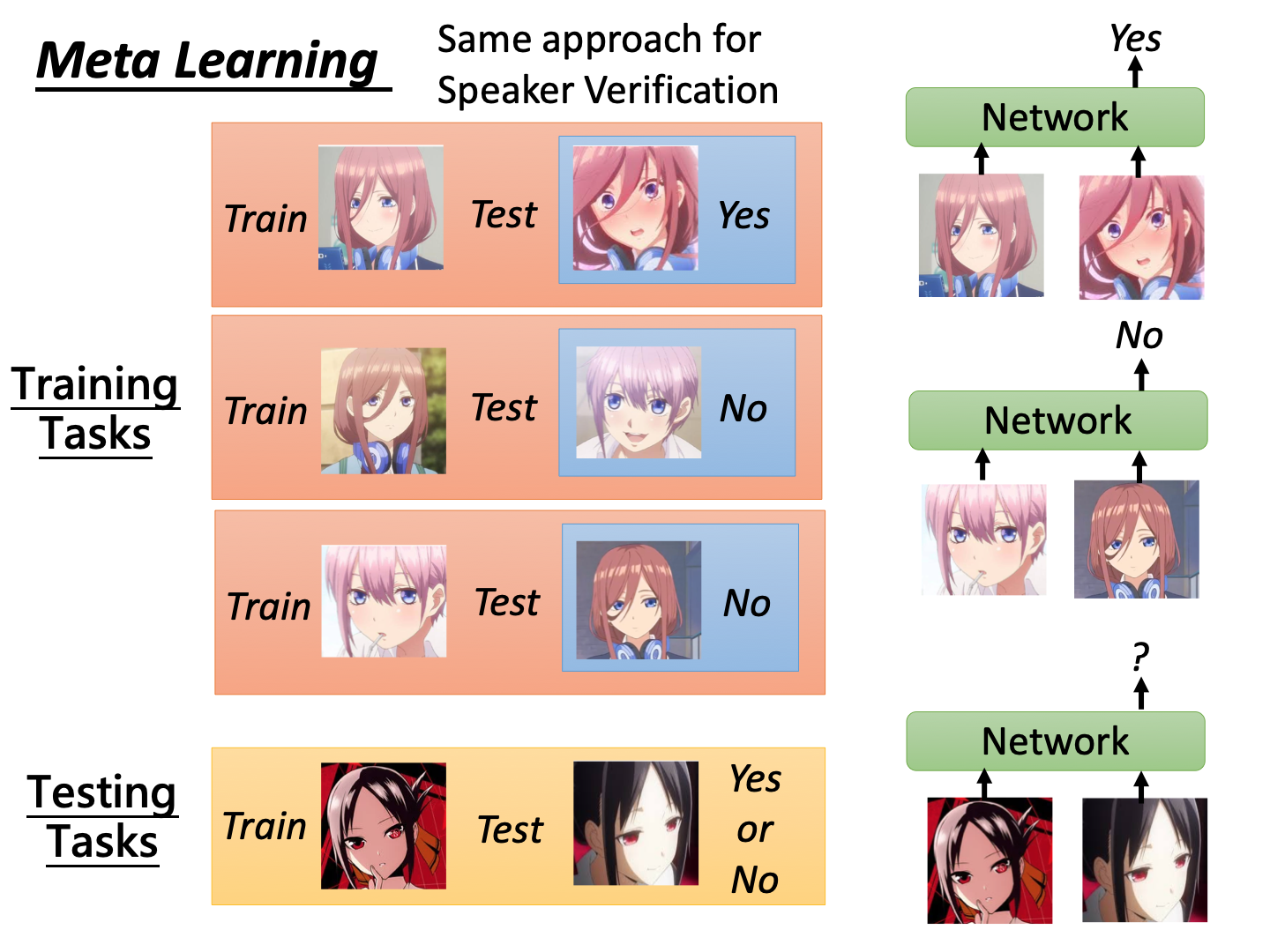
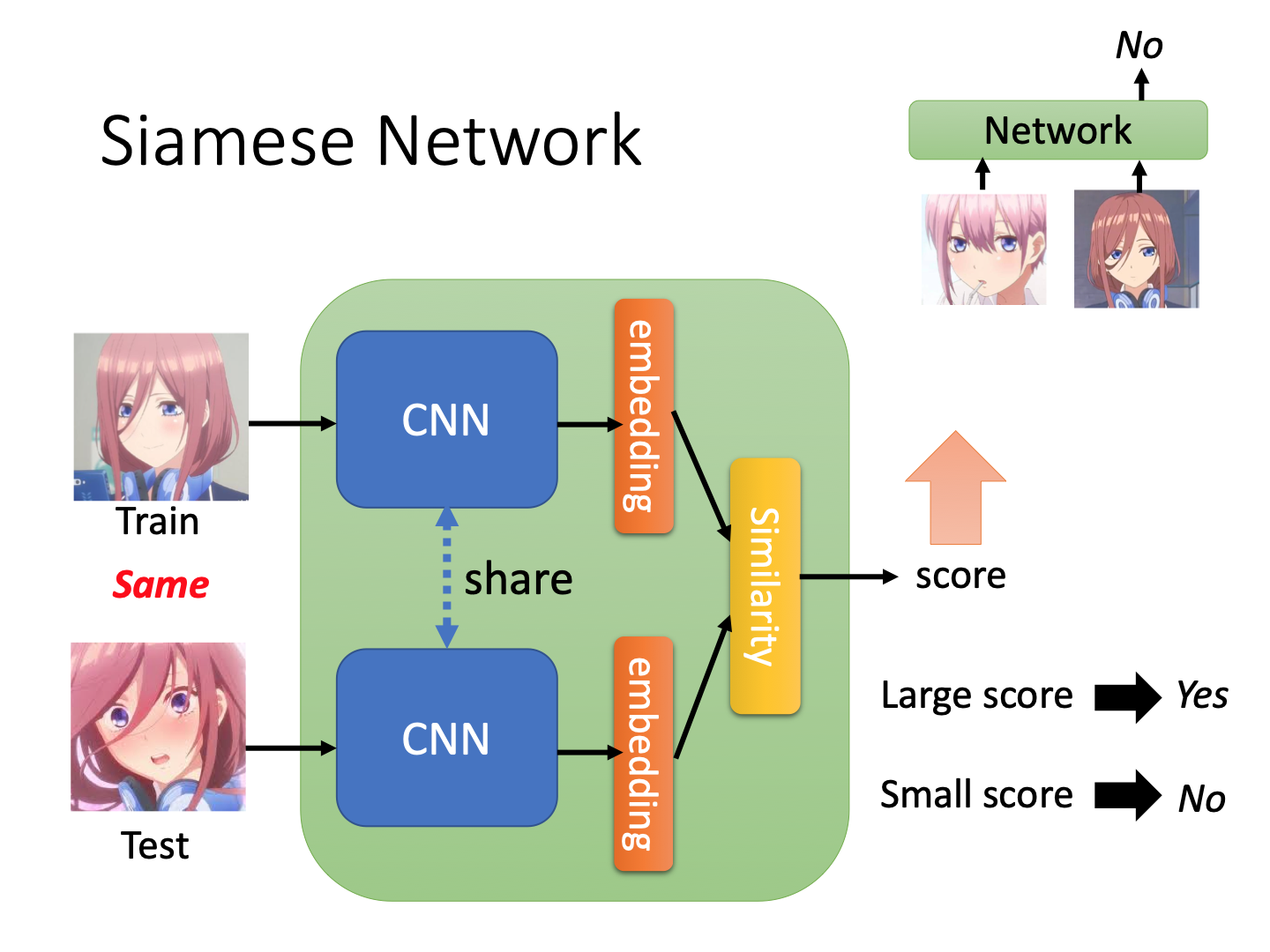
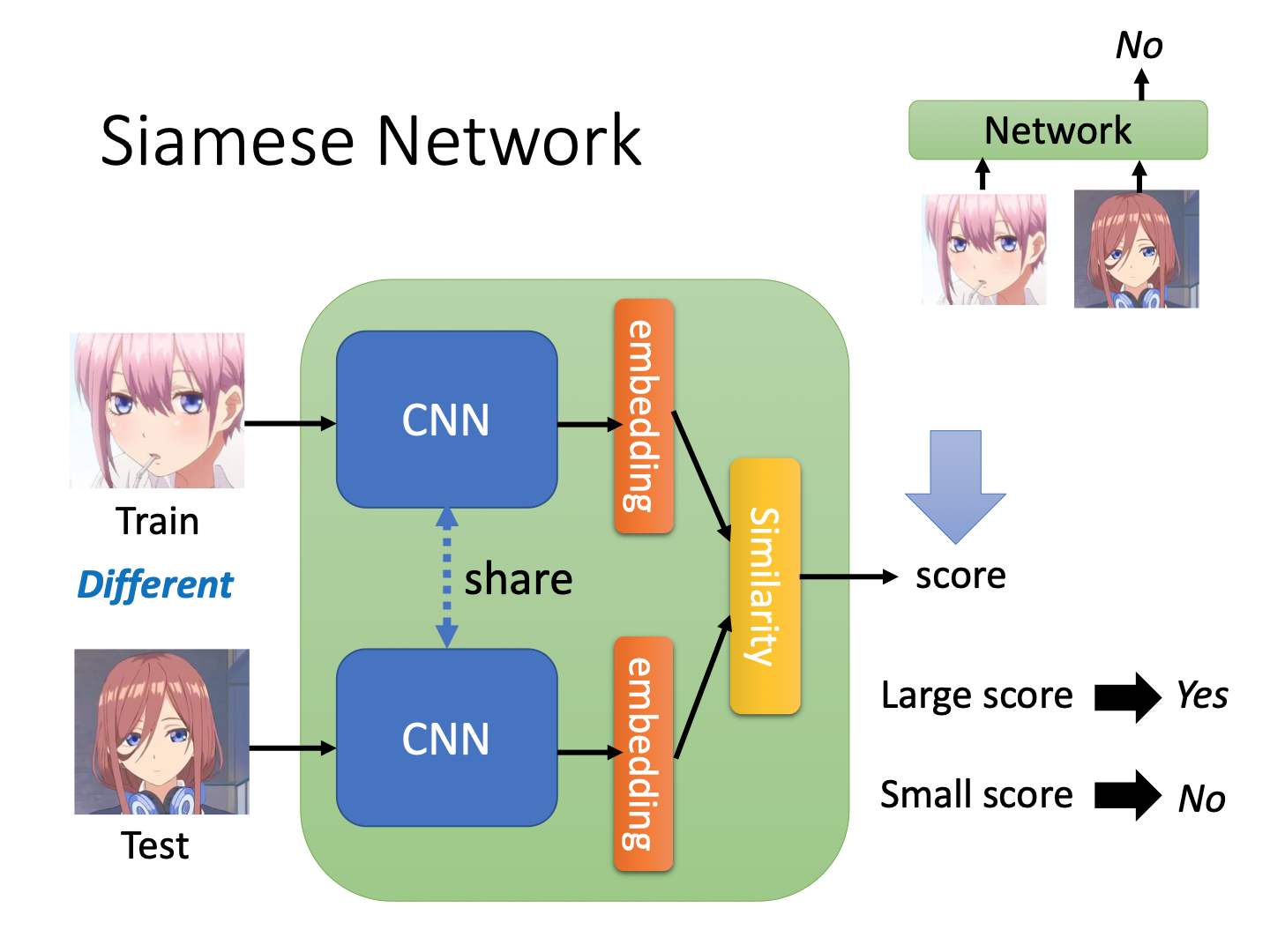
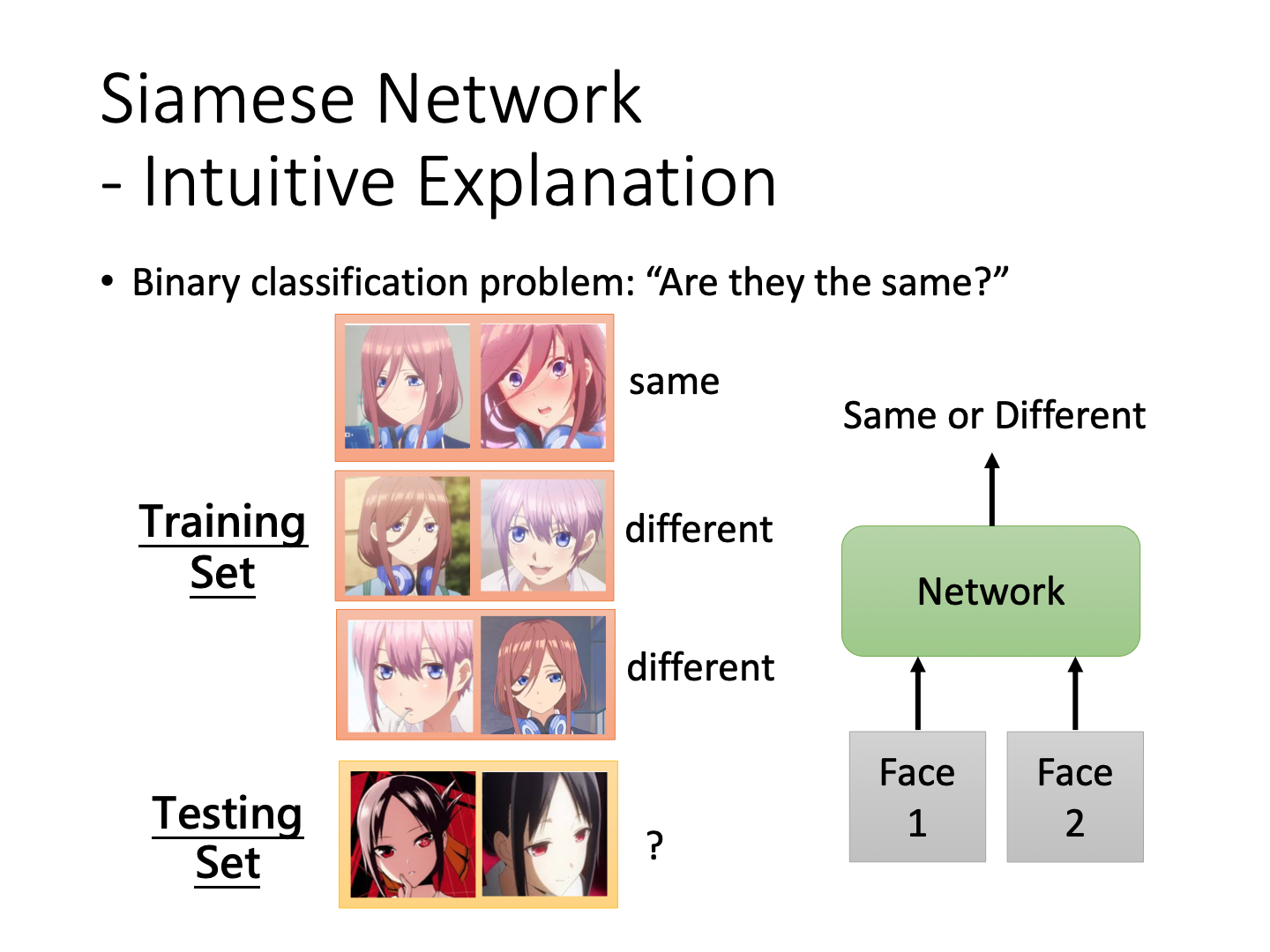
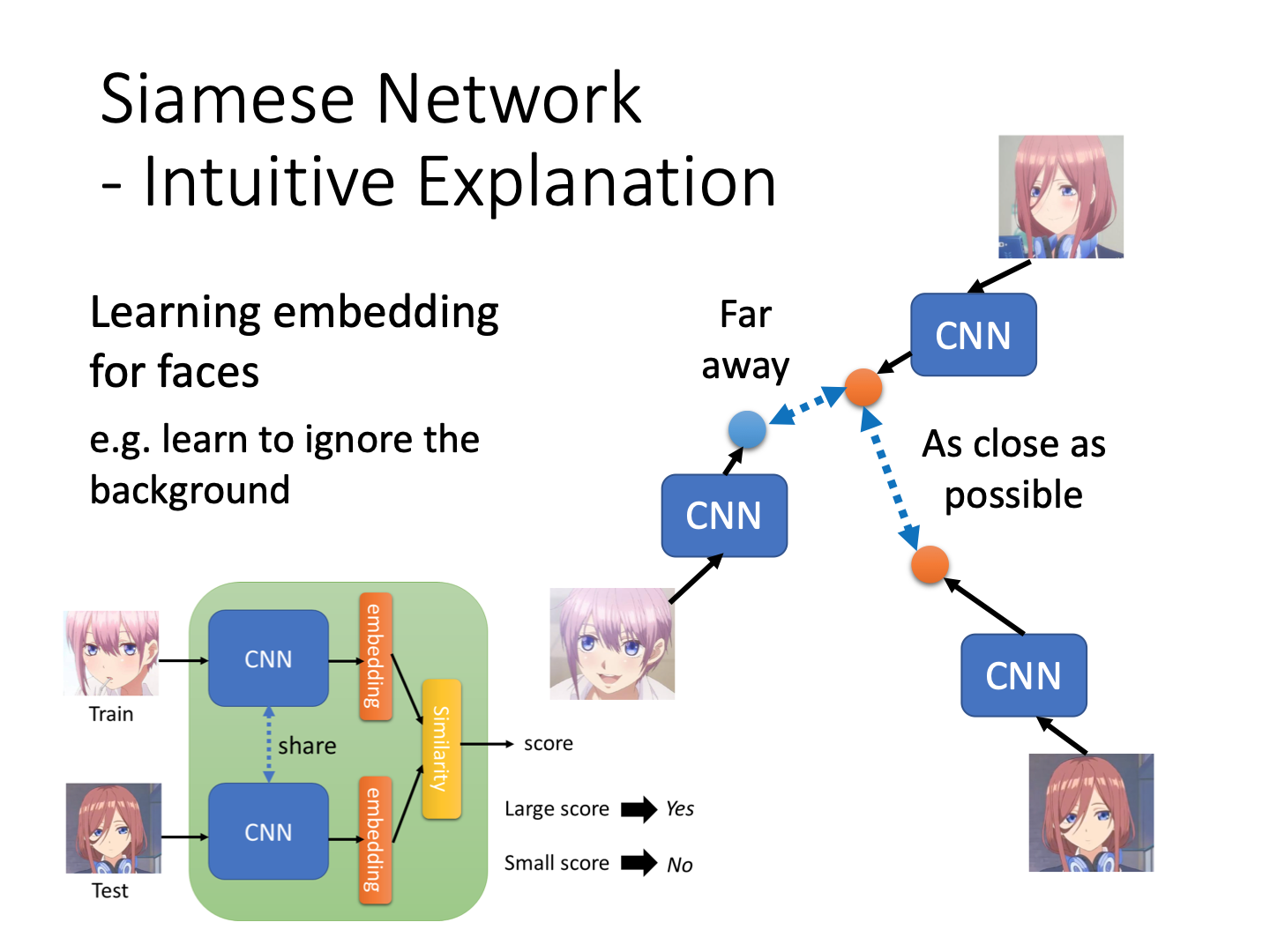
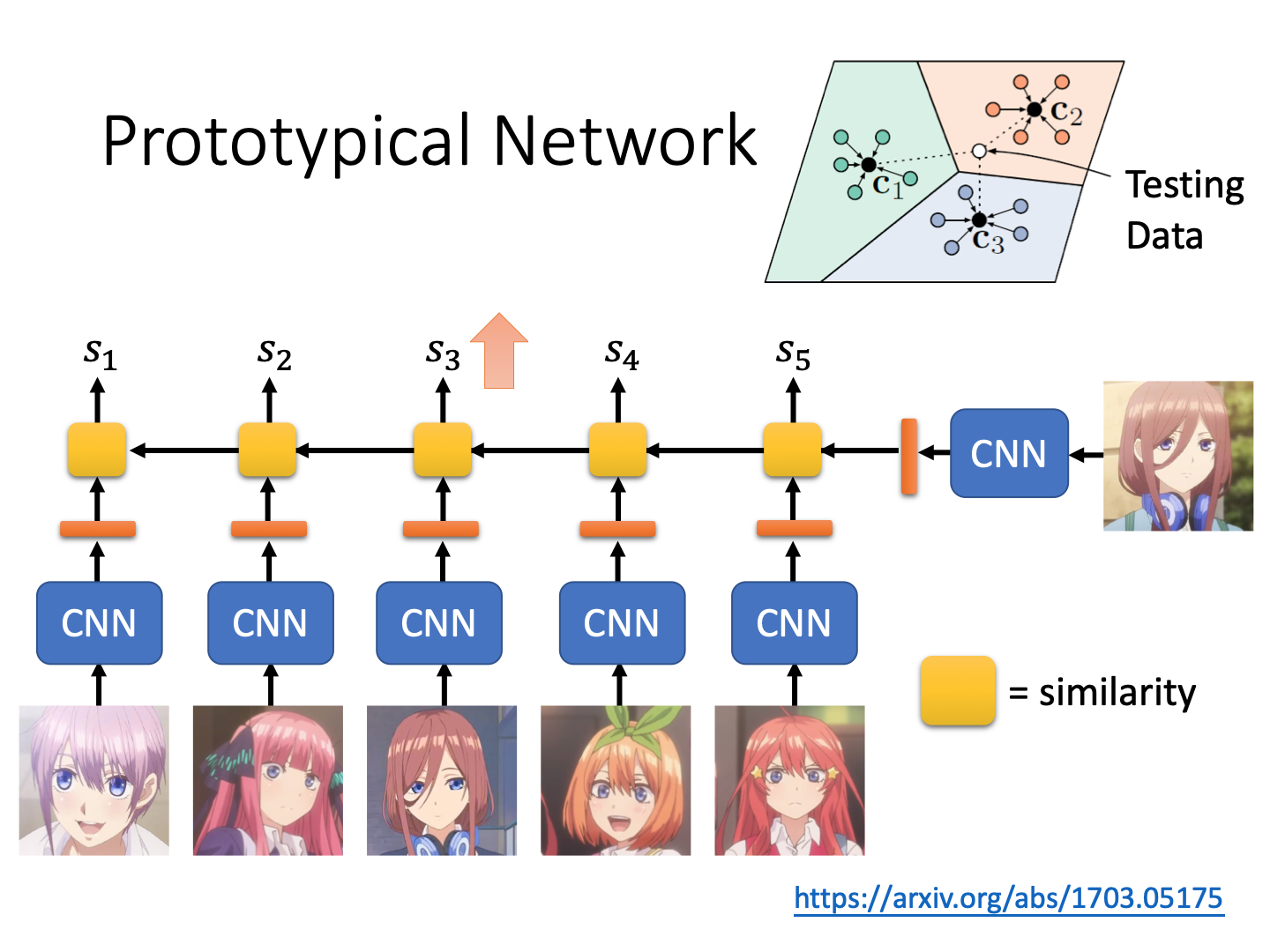
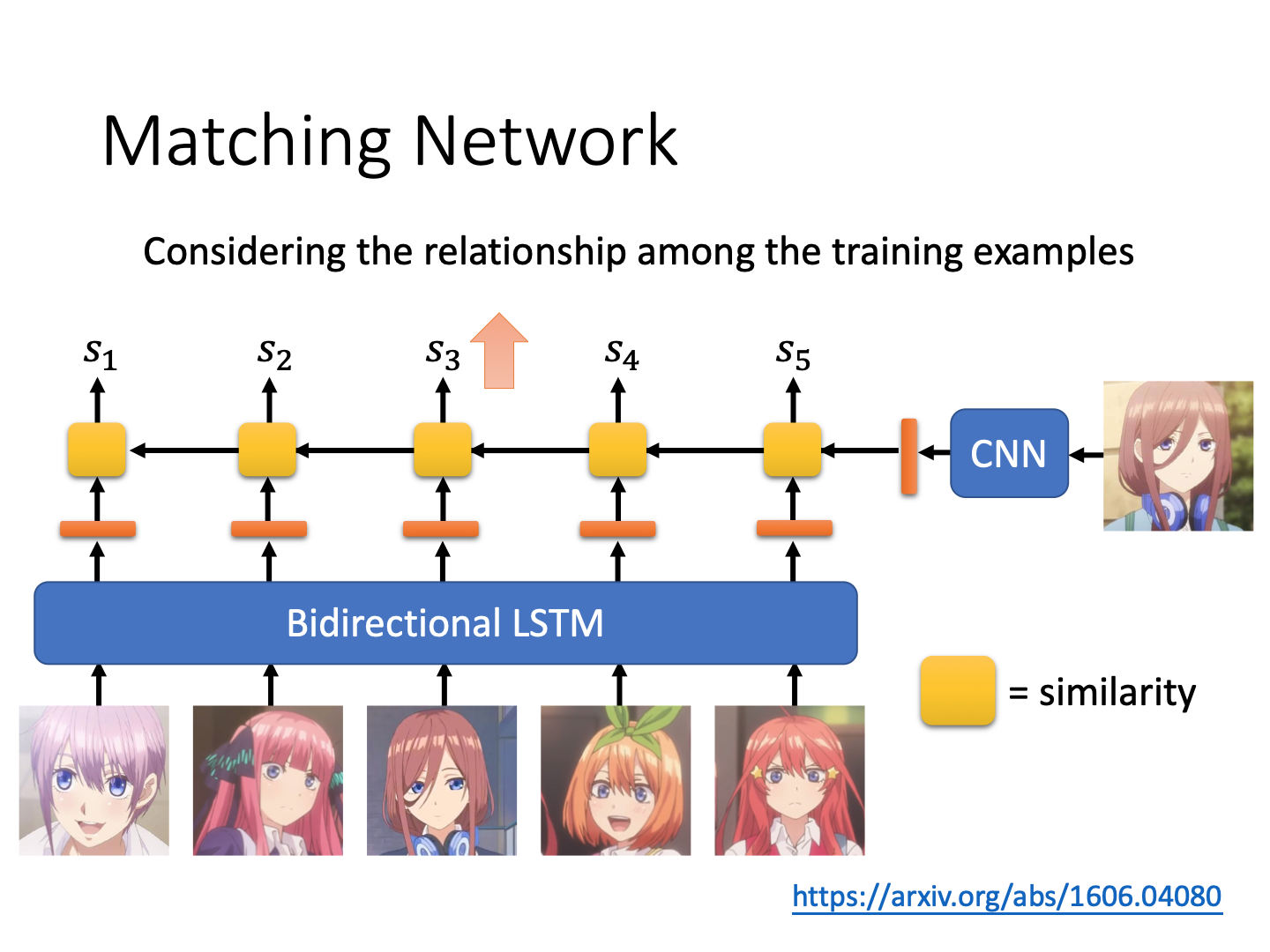
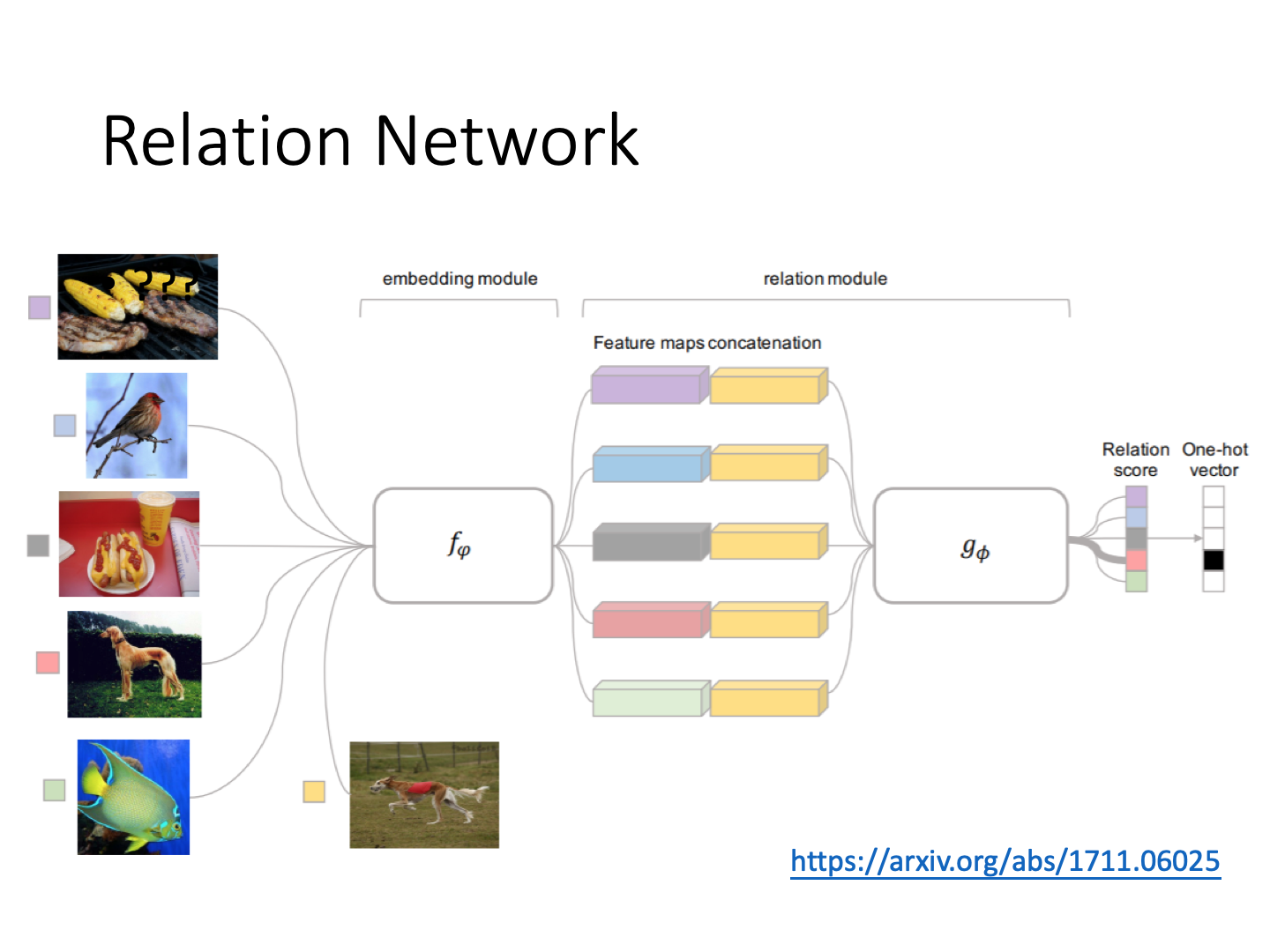
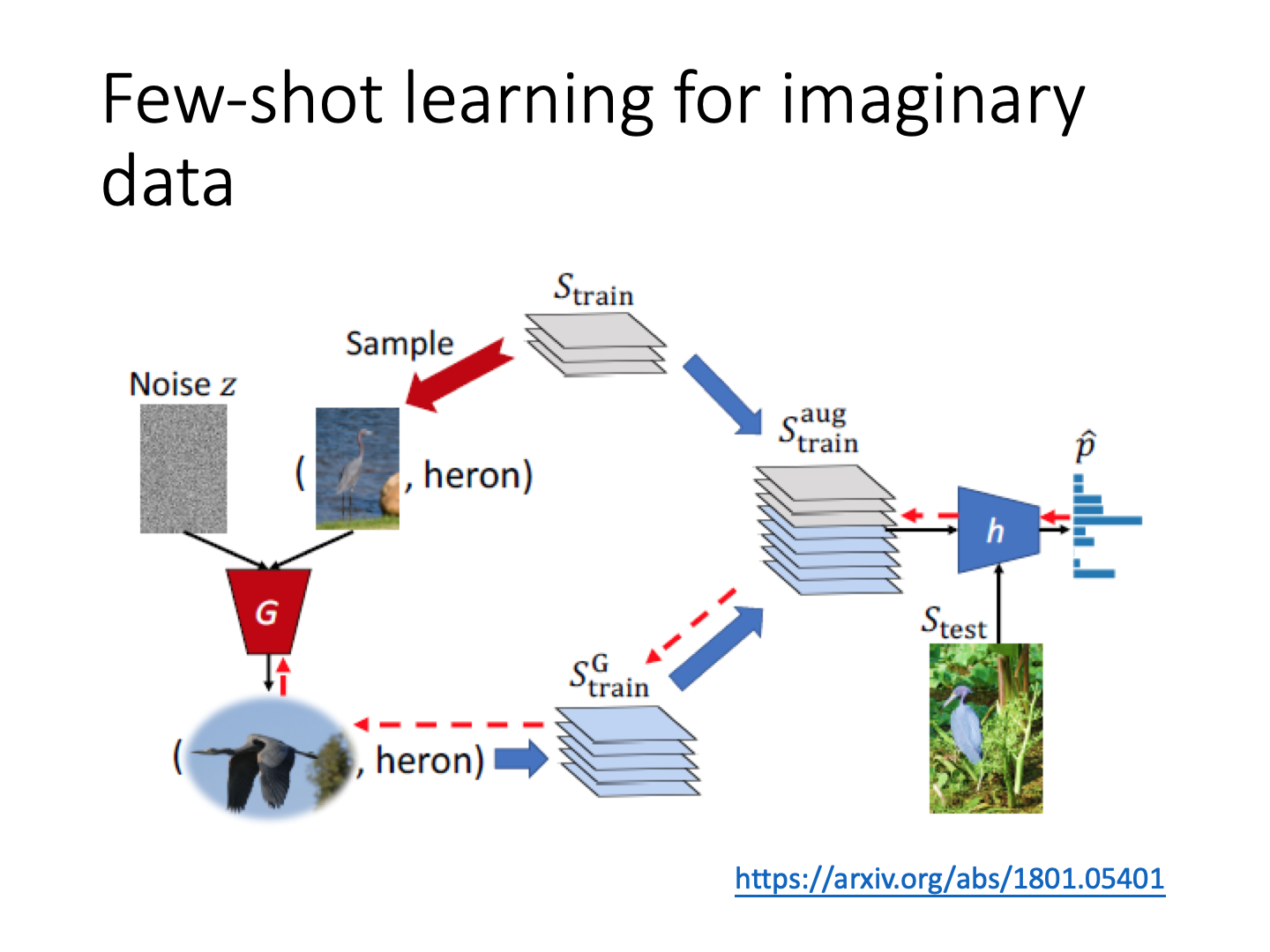
Metric-based Approach




转载地址:http://jxaji.baihongyu.com/